
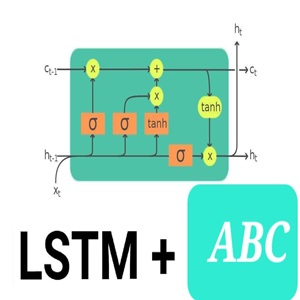
یادگیری ماشین
یادگیری ماشین یا همان Machine Learning (ML) یک زمینه مهم در علوم کامپیوتر و هوش مصنوعی است که به کامپیوترها این امکان را میدهد تا بدون برنامهریزی صریح، از دادهها یاد بگیرند و الگوها و قوانینی را کشف کنند. این فرآیند به وسیلهٔ الگوریتمها و مدلهای ریاضی انجام میشود.
یادگیری ماشین به چهار دسته اصلی تقسیم میشود:
1. یادگیری نظارت شده (Supervised Learning):
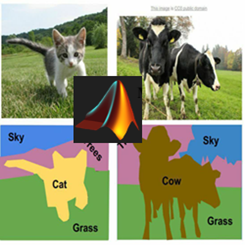
در این نوع یادگیری، مدل با استفاده از یک مجموعه از دادههای ورودی که شامل جفتهای (ورودی، خروجی متناظر) هستند، آموزش میبیند. هدف این است که مدل بتواند از ورودیهای جدید، خروجی متناظر را پیشبینی کند. مثالهایی از یادگیری نظارت شده شامل پیشبینی قیمت خانه بر اساس ویژگیهای مختلف یا تشخیص تصاویر (مثل تشخیص گربه و سگ) میشوند.
2. یادگیری بدون نظارت (Unsupervised Learning):
در این حالت، مدل بدون دسترسی به خروجیهای مطلوب، سعی در کشف الگوها و ساختارهای مخفی در دادهها دارد. مثالهایی از یادگیری بدون نظارت شامل خوشهبندی دادهها به گروههای مشخص یا کاوش موضوعات در متون بدون برچسب هستند.
3. یادگیری تقویتی (Reinforcement Learning):
در این نوع یادگیری، مدل یک عامل (agent) با تعامل با یک محیط، تجربه میکسبد و با انجام اعمال مختلف، بهبود عملکرد خود را ادامه میدهد. سیستمهای مبتنی بر یادگیری تقویتی معمولاً در زمینههایی مانند بازیهای رایانهای یا رباتیک به کار میروند.
4. یادگیری شبه/نیمه نضارتی (Semi-Supervised Learning):
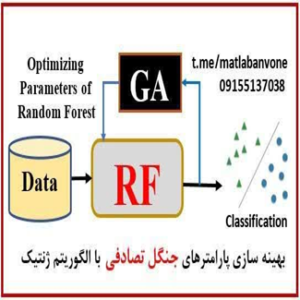
برخی از الگوریتمهای یادگیری ماشین شناختهشده برای رگرسیون و طبقه بندی شامل ماشینهای بردار پشتیبان (Support Vector Machines)، شبکههای عصبی (Neural Networks)، درختهای تصمیم (Decision Trees)، جنگل تصادفی Random Forest، روش های بوستینک CatBoost, AdaBoost, XGBoost, LSBoost، انفیس ANFIS، نزدیکترین همسایه KNN، بیزین ساده، و الگوریتمهای خوشهبندی مانند K-Means، سلسله مراتبی، فازی سزمینز Fuzzy C-Means، DBSCAN، … هستند.
نمایش 1–9 از 83 نتیجه
-

-
-
-

-

-
 انتخاب ویژگی
انتخاب ویژگیآموزش جامع تشخیص نفوذ در دیتاست UNSW-NB15 با یادگیری ماشین و انتخاب ویژگی
1,480,000تومان -

-
 آموزشهای رایگان
آموزشهای رایگانآموزش رایگان الگوریتم ماشین بردار پشتیبان SVM بخش اول تئوری
-
 آموزشهای رایگان
آموزشهای رایگانآموزش رایگان الگوریتم ماشین بردار پشتیبان SVM بخش دوم متلب